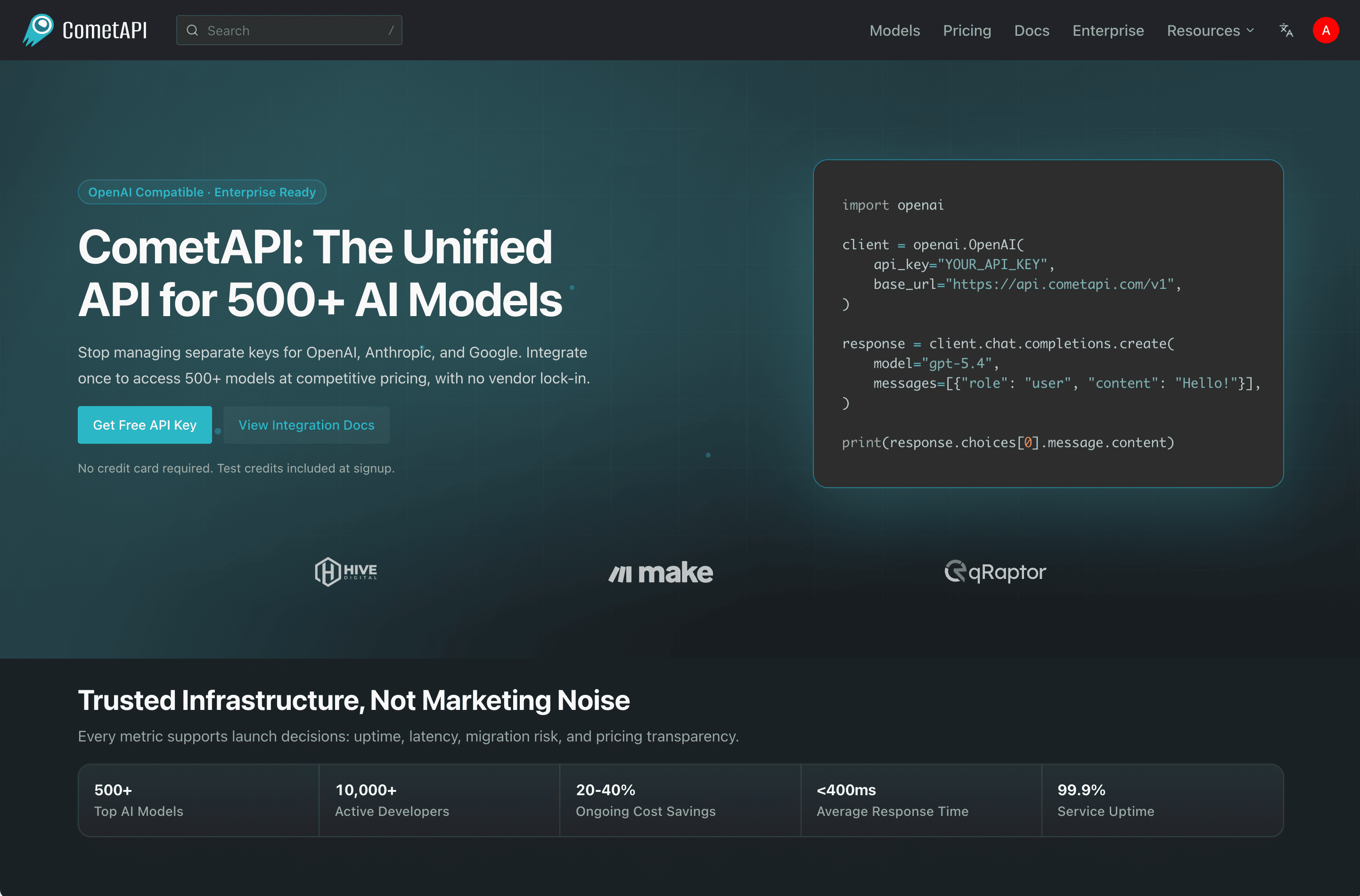
CometAPI is a unified AI API gateway that gives developers one OpenAI-compatible key to access 500+ AI models — including GPT, Claude, Gemini, and DeepSeek — at 20% or more below official pricing. Instead of juggling separate accounts, keys, and billing for OpenAI, Anthropic, and Google, you integrate once and switch models by changing a single line of code.
What Is CometAPI?
CometAPI is a single API platform that aggregates large language models and multimodal models behind one endpoint and one credential. Its core promise is simple: “Stop managing separate keys for OpenAI, Anthropic, and Google.” Because the API is OpenAI-compatible, teams that already use the OpenAI SDK can point their existing code at CometAPI and immediately reach hundreds of additional models without re-architecting their stack.
This makes CometAPI an LLM API gateway — infrastructure that sits between your application and every major model provider, handling authentication, routing, billing, and analytics in one place.
Key Features
- One API key for everything — Replace separate OpenAI, Anthropic, and Google credentials with a single CometAPI key.
- OpenAI-compatible API — Existing OpenAI SDK code works without refactoring; just update the
base_url. - Instant model switching — Change models with one line of code and zero vendor lock-in.
- Pay-as-you-go billing — No monthly subscription, no minimum spend, and credits that roll over with no expiration.
- Real-time analytics — Usage dashboards with spend tracking and budget alerts on a single unified invoice.
- Enterprise privacy — Data is never used for model training, and prompts are not logged.
Supported AI Models
CometAPI provides access to 500+ models across every major modality:
- Chat & text: GPT, Claude (Fable 5, Opus 4.8), Gemini (3.5 Flash, 3.1 Pro), DeepSeek, Grok, Kimi, and MiniMax.
- Image generation: GPT Image 2 and FLUX.
- Video generation: text-to-video and image-to-video models.
- Multimodal & documents: image-to-text and PDF-to-text workloads.
CometAPI Pricing
CometAPI is pay-as-you-go with every model priced at a minimum of 20% below official provider rates (often 20–40% cheaper). There is no subscription and credits never expire. Representative published pricing per 1M tokens:
| Model | CometAPI | Official | Savings |
|---|---|---|---|
| Claude Fable 5 | $8 | $10 | 20% |
| Claude Opus 4.8 | $4 | $5 | 20% |
| Gemini 3.5 Flash | $1.2 | $1.5 | 20% |
| Gemini 3.1 Pro | $1.6 | $2.0 | 20% |
| Kimi K2.7 Code | $0.76 | $0.95 | 20% |
| MiniMax-M3 | $0.48 | $0.6 | 20% |
For high-volume teams, CometAPI offers flexible discounts at scale and an enterprise tier with dedicated servers and unlimited RPM/TPM.
Integrations & Compatibility
One CometAPI key works across the tools developers already use:
- Coding agents: Claude Code, Codex, Cline, and OpenClaw.
- Automation platforms: n8n, Zapier, and Make.
- App builders: Coze and Dify.
Because the endpoint is OpenAI-compatible, any framework or SDK that speaks the OpenAI format — LangChain, Cursor, and similar tools — can connect with only a base URL change.
How to Get Started
Getting running takes four steps:
- Sign up for free — no credit card required.
- Get your API key — a single credential for all 500+ models.
- Update your
base_url— point your existing OpenAI SDK at CometAPI. - Build and scale — pay only for what you use.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.cometapi.com/v1",
)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Hello!"}],
)
print(response.choices[0].message.content)
Who Should Use CometAPI
- SaaS and app developers embedding AI features who want to avoid provider lock-in.
- Enterprise teams centralizing AI spend under one invoice and dashboard.
- Automation builders wiring models into n8n, Make, and Zapier workflows.
- Researchers and prototypers comparing many models without opening an account for each.
Why Choose CometAPI
CometAPI’s strongest differentiators are breadth, compatibility, and cost: 500+ models behind one OpenAI-compatible key, instant switching with no lock-in, and pricing that runs 20–40% below official rates — backed by a stated 99.9% uptime and sub-400ms average response time. For any team building on more than one model, it removes the integration tax of maintaining multiple provider SDKs, keys, and invoices.